




Key Takeaways
Solidroad is the only Klaus alternative that monitors AI agent conversations (Fin, Decagon, Sierra) natively and auto-generates training simulations from QA findings.
MaestroQA (now Rippit) is the strongest option for screen capture and configurable AI Auto QA across non-Zendesk helpdesks.
Scorebuddy is the most accessible entry point, with a 14-day free trial and tiered pricing for SMB teams moving up from spreadsheet-based QA.
Observe.AI serves large enterprise voice centers with compliance requirements, but needs dedicated internal resources to maintain.
Every tool in this list except Solidroad stops at QA scoring - none automatically connects QA findings to agent training.
Why teams switch from Klaus (Zendesk QA)
Teams leave Klaus (now Zendesk QA) for three reasons: the 2022 acquisition locked the product to Zendesk-only teams, the roadmap shifted toward Zendesk ecosystem features rather than standalone QA depth, and the platform was built for human agents before AI bots became a meaningful share of customer interactions.
Klaus was a genuinely good standalone QA tool. When Zendesk acquired it, users running Intercom, Freshdesk, or Salesforce had a straightforward problem: the product they’d been using got Zendesk’d. In 2026, there’s a second question on top of platform lock-in: which alternative can monitor the AI agents your team is deploying? Solidroad platform data shows 15-57% of AI agent responses contain errors - and most QA tools in this list weren’t built to catch them.
This guide compares seven Klaus alternatives - Solidroad, MaestroQA (now Rippit), Scorebuddy, EvaluAgent, Observe.AI, Playvox, and Level AI - evaluated on platform independence, AI agent monitoring, QA-to-training integration, and G2 social proof. Solidroad is our platform, and it appears first in this list. We’ve included honest limitations alongside strengths for every tool.
Klaus alternatives at a glance
The seven best Klaus alternatives in 2026: Solidroad (AI agent QA + training), MaestroQA/Rippit (screen capture + custom AI agent QA), Scorebuddy (customizable scorecards + LMS), EvaluAgent (compliance + engagement), Observe.AI (enterprise voice), Playvox (QA + WFM suite), and Level AI (multilingual conversation intelligence).
Tool | Best for | AI agent QA | Training integration | G2 rating |
|---|---|---|---|---|
Solidroad | AI agents + human agents; automated training from QA findings | Native - monitors Fin, Decagon, Sierra conversations | Auto-generated simulations from QA findings, scored against custom rubrics | 4.5 |
MaestroQA (now Rippit) | Screen capture + custom AI agent QA across non-Zendesk helpdesks | No native AI agent monitoring | No - separate coaching workflows only | 4.6 |
Scorebuddy | Customizable scorecards + built-in LMS for human agents | Human-in-loop monitoring only | Separate LMS module; manual QA-to-training assignment | 4.5 |
EvaluAgent | Compliance-focused QA + engagement tools for mid-market teams | No native AI agent monitoring | Manual coaching only; no auto-generated training | 4.5 |
Observe.AI | Enterprise voice centers with real-time agent assist + compliance monitoring | Monitors interactions, but also builds AI agents | No training simulation module | 4.4 |
Playvox | Teams consolidating QA, WFM, scheduling, and agent performance | No AI agent monitoring | Separate coaching module; no simulation generation | 4.3 |
Level AI | Multilingual contact centers needing conversation intelligence at scale | No native AI agent monitoring | Relies on manual coaching workflows | Not available |
How to evaluate QA tools in 2026
When evaluating Klaus alternatives, three criteria matter most: platform independence (not Zendesk-only), 100% automated conversation coverage instead of 1-5% manual sampling, and AI agent monitoring capability - what separates tools built for 2026’s contact centers from those designed for human-only teams.
Platform independence
Platform independence means QA software works regardless of which helpdesk you run. All seven alternatives in this list support multiple helpdesks. The key question: does the tool integrate with your specific stack - Intercom, Freshdesk, HubSpot, Salesforce - or only with Zendesk? An alternative that doesn’t connect to your helpdesk is a problem before it’s a solution.
Automated coverage vs. manual sampling
AI-powered QA tools score 100% of conversations automatically. Traditional manual QA reviewed 1-5% - meaning the vast majority of interactions were never evaluated. 100% coverage is now table stakes; every tool in this list claims it. The differentiation is what happens after the score lands.
In our State of CX 2026 report, 81% of agents say most of their conversations are never reviewed. For a team handling 50,000 interactions monthly, that’s 40,000+ conversations where compliance risks and coaching opportunities go undetected.
AI agent monitoring capability
AI agent monitoring means QA software evaluates conversations handled by AI bots - Intercom Fin, Decagon, Sierra - the same way it evaluates human agent conversations. Most QA tools were built before AI agents existed and can’t do this. Only tools with native AI agent evaluation can score bot responses for accuracy, tone, policy compliance, and hallucinations. Solidroad platform data shows 15-57% of AI agent responses contain errors. Without a QA tool watching those conversations, that error rate is invisible.
Tip - what to ask vendors about AI agent QA
Ask vendors specifically whether their tool evaluates AI agent output or only surfaces it in conversation logs. The distinction matters: monitoring means scoring bot conversations against the same quality rubrics used for human agents - flagging hallucinations, policy violations, and tone failures in real time.
The 7 best Klaus alternatives
The seven alternatives below are evaluated across AI agent monitoring, QA-to-training integration, platform compatibility, and G2 social proof.
1. Solidroad (best for teams deploying AI agents who need QA and training in one platform)
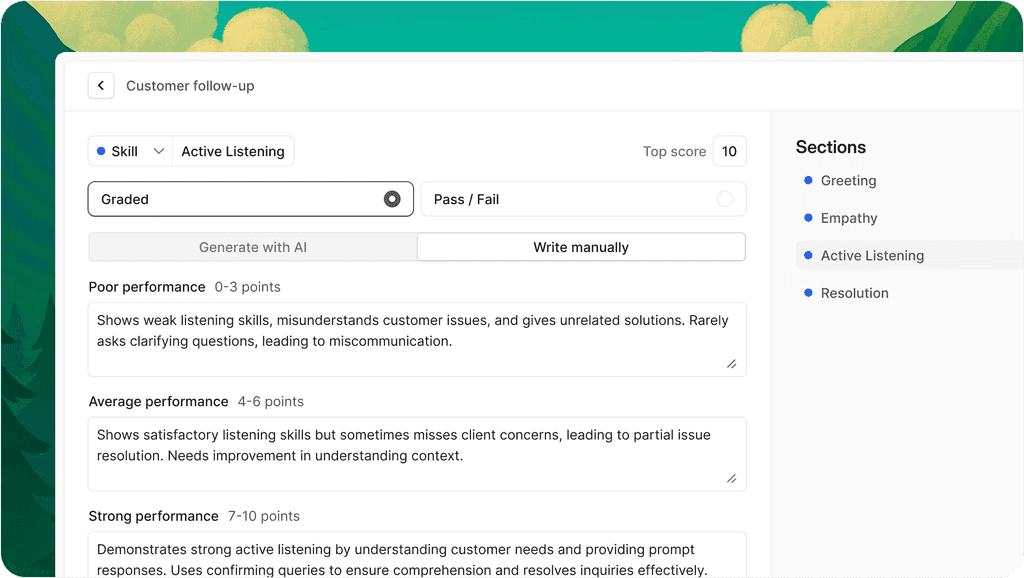
Solidroad is an AI-native QA and training platform that monitors both human and AI agent conversations, then automatically turns scoring findings into agent training simulations. It’s the only platform in this comparison that closes the gap between QA and training without requiring a manager to manually connect the two - and the only one built to handle the hybrid contact center where AI agents and human agents operate side by side.
Every other tool in this list scores conversations. Solidroad scores them and then does something structural with those scores: it generates training simulations based on the specific scenarios where agents or AI bots underperformed. An agent who scored poorly on de-escalation gets a simulated de-escalation conversation to practice against. An AI agent that produced a hallucinated response gets flagged and reviewed in real time. The loop from QA finding to corrective action is automatic.
AI agent QA - native, not bolted on
Solidroad scores 100% of conversations across both human and AI agents. For human agents, that’s a 20x QA coverage increase over manual sampling and 90% less time spent per review. For AI agents - Intercom Fin, Decagon, Sierra, Intercom Copilot - every conversation gets evaluated against your quality rubric, with hallucinations and policy violations flagged as they occur.
The 15-57% AI agent error rate reflects a real problem: most teams deploying AI support agents have no systematic way to catch errors at scale. The fix is automated QA across AI and human agents in the same workflow - the only architecture that scales with both.
Real-time risk detection means compliance issues, churn signals, and hallucination patterns surface immediately - not in the next weekly QA review. Teams at Ryanair, Crypto.com, and Fever use this to maintain quality standards across high-volume operations where manual sampling would miss most of what matters.
Hiring and onboarding
Solidroad handles more than in-service QA - teams use it to evaluate candidates and onboard new hires before they handle live conversations. Candidates complete AI-powered simulations in the hiring stage, giving hiring managers objective performance data alongside self-reported responses. For onboarding, new agents practice against the same scenarios used in live QA before their first real customer interaction.
One user described the impact directly: “In hiring we had multiple people using AI to answer the skill exercises. With Solidroad we’re fighting AI with AI and the experience is as similar as in real life and the feedback we get is very detailed.” This use case - hiring through onboarding through live QA on one platform - is distinct from every other tool in this comparison, where QA and training are separate products and hiring assessments are a third.
The QA-to-training loop
Our survey of 500 agents found that 53.5% identify the hardest part of ramping as applying training to real situations - not learning the process, but executing it under pressure. Classroom training teaches process; live conversations teach judgment. The gap between the two is where new agents stumble, escalate unnecessarily, and erode customer trust during their first weeks.
Solidroad closes that gap by turning QA scores into AI-powered training simulations automatically. When a conversation reveals a coaching opportunity - a missed de-escalation, a compliance gap, an AI hallucination - the platform generates a practice scenario from that exact interaction type.
Agents work through the simulation; their performance is scored against the same rubric that measures live calls. The simulation mirrors real conversation dynamics: the AI responds in real time, handles objections, and generates detailed per-turn feedback at the end. Managers see where each agent stands without scheduling a separate coaching session. The loop from finding to fix doesn’t require human coordination.
This is what distinguishes Solidroad architecturally from every other tool in this list: QA and training in one platform, connected by default.
Platform and trust signals
Solidroad works across Zendesk, Intercom, Freshdesk, HubSpot, Help Scout, ServiceNow, Gladly, and Gorgias. Teams that left Klaus because of Zendesk lock-in can run Solidroad on whatever helpdesk stack they’re already using.
Platform stats: 3M+ conversations scored, customers including Meta, Faire, Oura, Crypto.com, Ryanair, Podium, ActiveCampaign, and Fever. SOC 2 Type 2 and ISO 27001 certified. $25M Series A closed April 2026.
Limitations
Custom pricing needs a demo call - upfront cost comparisons aren’t possible without a sales conversation. G2 review volume is thin (3 reviews at time of writing), so independent social proof relies on platform data and named customer references rather than review counts. Teams with strict vendor evaluation criteria based on review volume will need to weight customer references and case study data more heavily, and Solidroad’s customer list - Meta, Ryanair, Crypto.com - provides that context.
“Solidroad has significantly enhanced and refined our recruitment processes and training content, while providing engaging and effective assessments. Their dedication to partnership and their flexible, client-first approach have made them an invaluable extension of our efforts.” - Kellyn, Quantanite, via Product Hunt
2. MaestroQA (now Rippit) (best for screen capture + custom AI agent QA across non-Zendesk helpdesks)
For teams that left Klaus because of Zendesk lock-in, MaestroQA is one of the strongest alternatives - it works across Salesforce, Intercom, Front, and Kustomer, and its AI Auto QA is the most configurable in this comparison. MaestroQA rebranded to Rippit in March 2026; the G2 page still uses the MaestroQA name and the core product remains the same.
Key capabilities
AI Auto QA with configurable AI Prompting templates for any scoring criteria, without engineering support.
Native screen capture alongside conversation scoring - the only tool in this list with this capability.
Non-Zendesk helpdesk support across Salesforce, Intercom, Front, and Kustomer.
Coaching and performance dashboards with deep KPI drill-downs.
Strengths
MaestroQA has the most configurable AI Auto QA in this comparison. AI Prompting templates let teams match exact scoring criteria without custom integrations. Screen capture is genuinely differentiated - BPO and compliance-heavy operations need visual documentation alongside transcript scoring, and only MaestroQA provides this natively.
Limitations
The rebrand to Rippit signals a strategic shift, raising questions about the QA product roadmap for buyers needing long-term vendor commitment to conversation scoring. MaestroQA doesn’t have an integrated training module - QA findings and coaching remain separate workflows.
What G2 reviewers say
“What’s great about MaestroQA is that it stops treating quality reviews like a simple ‘pass/fail’ test and turns them into a way to actually coach people. Instead of just grading agents, it uses real data to help them improve.” - Cyrill T.
3. Scorebuddy (best for customizable scorecards with accessible pricing and a built-in LMS)
Scorebuddy is a QA platform with 713+ G2 reviews, 15 consecutive G2 Leader quarters, and a 4.5 rating. It’s the most accessible entry point in this comparison, with a 14-day free trial and tiered pricing that scales from SMB to enterprise. Its scorecard builder lets teams tie scoring directly to compliance criteria, customer experience metrics, and operational KPIs.
Key capabilities
Customizable scorecards mapped to compliance, CX, and operational KPIs.
Built-in LMS for training content alongside QA scoring.
BI-grade reporting with data export.
Tiered pricing with a 14-day free trial.
Strengths
Scorebuddy’s scorecard builder makes QA a measurement tool rather than a checklist exercise. The built-in LMS means QA-to-learning workflows exist in one platform - though connecting QA findings to specific training content still requires a manager to make the assignment.
Limitations
Reporting can feel limited for teams needing advanced cross-team analytics without exporting to BI tools. The coaching module has documented reliability issues - multiple G2 reviewers report sessions failing to save. The LMS delivers traditional courseware rather than auto-generating training scenarios, so the QA-to-training loop needs manual coordination.
What G2 reviewers say
“Score buddy makes it easy to build scorecards tailored to your business goals. You can align scoring directly with compliance, customer experience, and operational KPIs - so QA isn’t just about finding mistakes, it’s about improving outcomes.” - Maricon B.
4. EvaluAgent (best for compliance-focused teams in regulated industries with built-in agent engagement tools)
EvaluAgent is a QA platform built for compliance-heavy, mid-market contact centers that need both automated evaluation workflows and agent engagement built in. It centralizes QA data so agents view their scores in real time and includes gamification features - badges, leaderboards, real-time feedback - that help maintain engagement with the QA process rather than just receiving scores.
Key capabilities
Automated QA workflows with smart assignment rules and calibration.
Real-time score visibility for agents.
Gamification including badges and leaderboards.
Data export without requiring BI or development layers.
Strengths
EvaluAgent centralizes QA data so agents view scores in real time - reducing the adversarial dynamic traditional QA programs create. Smart assignment rules and calibration workflows cut manual routing work for QA analysts.
Limitations
Multiple G2 reviewers describe EvaluAgent’s interface as complex with a learning curve. It relies on human-mediated coaching rather than automated training - identifying quality gaps but leaving the path from gap to improvement in managers’ hands.
What G2 reviewers say
“I think the fact that EvaluAgent keeps the data centralized is very important to me. I also like being able to export and share data consistently without having to go through layers of BI and development work.” - Andrew C.
5. Observe.AI (best for large enterprise contact centers needing voice intelligence and real-time agent assist)
Observe.AI scores 100% of voice interactions automatically and pairs post-interaction QA with real-time agent assist. It serves 350+ enterprise customers and holds SOC 2 Type II, HIPAA, and HITRUST certifications. For voice-heavy, regulated-industry contact centers at enterprise scale, it’s a strong fit.
One structural consideration: Observe.AI now builds VoiceAI agents as well as monitoring them. Teams running Fin or Decagon should ask whether a vendor that competes in AI agent deployment is the right choice for independent monitoring.
Key capabilities
100% automated voice conversation scoring with real-time agent assist.
Compliance monitoring with SOC 2, HIPAA, and HITRUST certifications.
Post-interaction QA coaching integrated with live guidance.
350+ enterprise customer track record.
Strengths
Observe.AI surfaces coaching opportunities and quality insights across 100% of voice interactions, with real-time guidance during calls. Compliance monitoring and audit trails suit regulated industries at enterprise scale.
Limitations
G2 reviewers consistently note that a dedicated internal resource is needed to maintain the platform post-launch. There’s no training simulation module - improvement relies on manual coaching. Pricing is structured for large enterprises, with minimum seat thresholds that exclude mid-market teams.
What G2 reviewers say
“Observe.AI stands out because it treats customer conversations as a real data asset - turning insights into coaching and performance improvements teams can act on right away, not just dashboards to look at.” - Elizabeth H.
“You will likely need a dedicated staff member to maintain it and educate other stakeholders on how to use it.” - Tim W.
6. Playvox (best for teams consolidating QA, workforce management, and agent performance in one platform)
For teams that want QA, workforce scheduling, and agent performance in one platform without managing multiple vendors, Playvox offers consolidation most pure-play QA tools can’t. It combines quality management with WFM scheduling and forecasting, agent gamification, and performance management in a single suite.
Key capabilities
Quality management paired with WFM scheduling and forecasting.
Agent gamification and performance management in one interface.
Native integrations with Salesforce, Zendesk, Intercom, and Kustomer.
Customizable QA scorecards with QA and support team collaboration tools.
Strengths
Playvox reduces vendor complexity by combining QA, workforce scheduling, and agent performance in one platform. Native integrations across major helpdesks make onboarding straightforward.
Limitations
QA is one module within a broader workforce suite - feature depth may be shallower than pure-play QA tools for teams whose primary need is conversation scoring. No AI agent monitoring or training simulation capability.
What G2 reviewers say
“Playvox Quality Management has been a valuable tool for streamlining our quality assurance processes. Customizable QA scorecards, clear performance insights, easy collaboration between QA and support teams.” - Anchal J.
7. Level AI (best for multilingual contact centers needing conversation intelligence with automated QA flagging)
Level AI is an AI-native conversation intelligence platform with strong transcript accuracy and Instascore automated flagging, designed for high-volume multilingual operations.
Key capabilities
Instascore automated flagging that surfaces conversations most likely to contain quality issues.
100+ language support with strong accuracy across non-English speakers.
Sentiment analysis, conversation tagging, and coaching tools.
Auto-scoring and smart search across large conversation volumes.
Strengths
Instascore flags conversations most likely to contain quality issues, so analysts focus review time on high-risk interactions rather than random sampling. 100+ language support is a genuine differentiator for multilingual operations where most competitors have accuracy gaps.
Limitations
Transcript accuracy degrades in calls with non-American accents or background noise, flagged by multiple G2 reviewers. Level AI doesn’t connect QA findings to agent training - fixing identified quality issues relies on manual coaching.
What G2 reviewers say
“What I like best about Level AI is how it combines AI-driven insights with human-level understanding. It doesn’t just flag issues - it highlights trends, sentiments, and coaching opportunities.” - Michelle R.
The QA gap none of these tools close on their own
Every Klaus alternative in this list finds quality problems. None automatically turn those findings into agent training - that’s the gap every QA team eventually hits, and it’s structural: QA and training have historically been separate product categories, not separate features on a single roadmap.
Our State of CX 2026 report found that 53.5% of agents identify the hardest part of ramping as applying training to real situations. 82.5% feel prepared when they start - but applying that training in live conversations is the number-one challenge they report. Agents feel ready until a real customer interaction demands it.
Data callout - the preparedness paradox
82.5% of agents feel prepared when they begin. 53.5% say applying training to real situations is the hardest part of the job. That gap is where QA-only tools stop working.
The gap is structural: QA tools surface problems, training tools fix them, and they’ve historically been separate products with manual steps connecting them.
The problem with that split is timing. A QA finding has its highest coaching value immediately after the conversation it describes. When the path to training runs through a manager’s inbox and a scheduled session, the teaching moment is gone.
Solidroad closes this gap by making QA and training a single continuous loop - scores auto-generate training scenarios, agents practice the exact scenario they got wrong, and performance is measured against the same rubric as live calls.
How to switch from Klaus (Zendesk QA)
Switching from Klaus (Zendesk QA) involves three steps: exporting your historical QA data and scorecard configurations, confirming your new tool integrates with your existing helpdesk, and running a parallel period to validate that automated scoring matches your quality criteria before full cutover.
Data portability varies by vendor - ask about export formats before committing. Every alternative in this list supports the major helpdesks, and most include implementation support. The parallel-run period is where migration timelines slip - two to four weeks running both tools lets you calibrate automated scoring against your existing standards before switching fully.
Frequently asked questions
Is Klaus the same as Zendesk QA?
Klaus and Zendesk QA are the same product. Zendesk acquired Klaus in 2022 and rebranded it. The key constraint: Zendesk QA now only works within the Zendesk ecosystem, making it inaccessible to teams using Intercom, Freshdesk, Salesforce, or other helpdesks.
What is AI-powered quality assurance?
AI-powered quality assurance means using AI to score 100% of customer conversations automatically - replacing the manual process of reviewing 1-5% of interactions. Every conversation gets evaluated against a defined quality rubric (tone, policy compliance, resolution accuracy, agent performance) without a QA analyst listening to each recording individually.
Can QA tools monitor AI agents?
Most QA tools can't - they were built for human-to-customer conversations and weren't designed to evaluate bot outputs. Tools like Solidroad have native AI agent monitoring, evaluating Fin, Decagon, Sierra, and similar AI agents against the same quality rubrics applied to human agents - flagging hallucinations, policy violations, and tone failures in real time. Most tools in this comparison lack that capability.
What is the difference between QA software and training software?
QA software finds quality problems; training software fixes them. Most QA platforms stop at the finding - reporting scores to managers and leaving improvement to manual coaching outside the platform. Solidroad is the only platform in this comparison that does both: it turns QA findings into practice simulations automatically, closing the loop from scoring to improvement without requiring a manager to connect the two.
Make the switch count
You're not just replacing Klaus. You're choosing the QA architecture your team will run for the next several years - and in 2026, that decision has a dimension that didn't exist when Klaus was built.
Every tool in this list scores conversations. The question is whether your QA platform can watch your AI agents with the same rigor it applies to your human team, and whether it does anything useful with what it finds.
For teams where automated QA scoring is the ceiling, MaestroQA, Scorebuddy, EvaluAgent, Observe.AI, Playvox, and Level AI all have genuine strengths. For teams deploying AI agents alongside human agents - or anyone who's hit the wall where QA surfaces problems but coaching still falls through the gaps - Solidroad is the only alternative built to close that loop automatically.
See how Solidroad works to understand what a QA platform looks like when it's designed for how contact centers actually operate in 2026.


