7 Best MaestroQA Alternatives for QA and Agent Training (2026)

Mark Hughes
CEO & Co-Founder

Key takeaways
Solidroad is the only tool in this list that integrates QA scoring with AI training simulations - quality gaps trigger practice scenarios automatically.
53.5% of agents say applying training to real situations is their biggest challenge (State of CX 2026, 500 agents) - the tool you choose determines whether QA findings actually change behavior.
MaestroQA rebranded to Rippit in March 2026, shifting positioning from QA to conversation analytics - teams evaluating it today are evaluating a platform in transition.
Why teams look for MaestroQA alternatives
Teams look for MaestroQA alternatives for three reasons: limited sampling coverage, the Rippit rebrand shifting the product away from QA, and the gap between QA findings and agent behavior change. Which reason applies determines what you should prioritize in a replacement.
On March 4, 2026, MaestroQA rebranded to Rippit - away from QA as a core identity, toward conversation analytics. Rippit founder Vasu Prathipati said publicly: "QA is branded in people's minds as the past in an AI-first world." The core scorecard-and-coaching infrastructure remains intact. But teams evaluating it today are evaluating a platform in active transition.
MaestroQA's Lessonly integration - which previously bridged QA findings to training content - is gone after Seismic acquired Lessonly. Teams that relied on that workflow now face a manual handoff between QA findings and whatever training system they run separately.
QA without training is diagnosis without treatment. In our State of CX 2026 report - a survey of 500 customer support agents - we found that 53.5% of agents say the hardest part of their job is applying training to real situations. The tools on this list vary widely in how well they bridge that gap. Only one closes it automatically.
This article specifically explores alternatives to MaestroQA (now Rippit). Solidroad is our platform, and it appears first in this list. We've included honest limitations alongside strengths for every tool.
Tools were selected based on search ranking for this query and a forced inclusion list of direct competitors, then evaluated on QA coverage, AI agent monitoring, QA-to-training integration, and implementation reality.
MaestroQA alternatives at a glance
The seven alternatives below differ most on one axis: what happens after a quality gap is identified. Solidroad auto-generates training simulations from QA findings. Scorebuddy and EvaluAgent offer LMS access as a separate step. The rest surface coaching recommendations without automating the practice.
Solution | Best For | QA Coverage | AI Agent Monitoring | QA-to-Training Integration |
|---|---|---|---|---|
Solidroad | Teams that need 100% QA coverage AND want quality findings to automatically trigger agent training simulations | 100% automated across chat, email, voice, and AI agents | Supported - dedicated AI agent QA product with hallucination and error detection | Auto-generated: QA gap triggers AI simulation; agent practices the exact scenario |
Playvox | Teams that want QA alongside WFM, gamification, and engagement tools in one suite (now NICE-owned) | Automated QA with AI sentiment classification | Not confirmed for AI agents | Coaching analytics - no integrated training simulations |
Scorebuddy | Teams that want structured QA scorecards with a built-in LMS and three-tier pricing | AI autoscoring (500-1,000 credits/month by tier) | Not confirmed for AI agents | LMS add-on available - manual connection between QA findings and training content |
Observe.AI | Enterprise contact centers needing speech analytics, real-time agent guidance, and compliance monitoring | Automated QA with conditional scorecard logic | Not confirmed for AI agents | Coaching recommendations from evaluations - no automated training trigger |
EvaluAgent | Teams that want full-coverage automated QA with gamification and transparent per-user pricing | 100% automated coverage with speech and text analytics | Not confirmed for AI agents | LMS integration available - separate step from QA findings |
Level AI | Teams investing in AI-first conversation intelligence beyond standard QA scoring | 100% automated with semantic understanding claimed | Not confirmed for AI agents | Coaching recommendations - no integrated training simulations |
Zendesk QA (Klaus) | Teams already on Zendesk that want native QA with AutoQA and AI agent monitoring without a separate integration | AutoQA on every interaction including AI agents | Supported - AutoQA monitors AI agent interactions per Zendesk product data | No integrated training simulations |
Schedule an expert-run, 30 minute tour of the platform

How to evaluate MaestroQA alternatives
When evaluating MaestroQA alternatives, go beyond coverage rates and AI scoring - most tools now offer both. The differentiating questions: does the tool monitor AI agent responses? Does it close the loop between a quality finding and a training action? How transparent is pricing and switching cost?
QA coverage and AI scoring
QA coverage rate separates tools into two camps: manual sampling (1-5% of interactions) and automated 100% coverage. The camp you're in determines how much of your quality problem stays invisible. In our State of CX 2026 report, we found that 81% of support conversations are never reviewed - manual QA was designed before AI made full coverage feasible.
Solidroad, EvaluAgent, Level AI, and Observe.AI claim 100% automated coverage. Scorebuddy's AI autoscoring runs on a credit model (500-1,000 credits/month by tier). Zendesk QA's AutoQA covers every interaction including AI agent responses.
AI agent monitoring
Most QA tools in this list were not built to score AI agent responses - and 15-57% of those responses contain errors before QA processes are in place, based on our platform data from 3 million+ scored interactions. As AI agents handle more support volume, that gap becomes a real quality risk.
Solidroad's AI agent QA product monitors chatbot responses for hallucinations, policy violations, and incomplete answers. Zendesk QA's AutoQA also monitors AI agent interactions per Zendesk product data. For teams deploying Fin, Decagon, Sierra, or Intercom Copilot, this is a meaningful capability gap in the other tools on this list.
QA-to-training integration
Most QA tools treat quality and training as separate workstreams: you export a score, hand it to a trainer, and hope something changes. Tools that integrate QA findings directly into training workflows create a closed loop - a failing score triggers a practice scenario, the agent rehearses, and improvement is measurable. Only one tool in this list closes that loop automatically.
The tools in this census take three approaches:
Fully integrated: Solidroad automatically generates AI practice training simulations from QA gaps - a failing score fires a practice scenario, scored against the same rubric
Partial integration: EvaluAgent and Scorebuddy include LMS access, but connecting a QA finding to a training action is a manual step
No integration: Playvox, Observe.AI, Level AI, and Zendesk QA surface coaching analytics but offer no automated path from score to practice
Our survey data makes the stakes clear: 53.5% of agents say applying training to real situations is their single biggest challenge. A QA tool that surfaces gaps without closing them solves half the problem.
Implementation and switching costs
Switching QA tools carries real costs: data migration, scorecard rebuilds, and team retraining. Scorebuddy's 14-day free trial signals a faster onboarding path. Observe.AI reviewers on G2 note the platform needs a dedicated staff member to maintain it. For teams migrating from MaestroQA, the rebrand complicates things: existing Rippit customers should ask vendors explicitly whether their scorecard logic and historical QA data are portable.
About MaestroQA (now Rippit)
MaestroQA rebranded to Rippit in March 2026. Scorecard flexibility and structured coaching workflows remain intact - Rippit is among the most configurable QA tools in the market for complex conditional scoring logic. What changed: the Lessonly integration that previously bridged QA findings to training was eliminated after Seismic's acquisition, leaving a manual handoff. The rebrand toward conversation analytics also signals where the product roadmap is heading.
Rippit is the right fit for teams that need highly configurable QA scorecards and structured coaching analytics, and are comfortable managing training workflows outside the QA tool.
The 7 best MaestroQA alternatives
The seven tools below answer the same question from different angles: what happens after you find a quality gap? Where each lands on that axis shows you which is the right replacement for your program.
1. Solidroad (best for QA + integrated agent training)
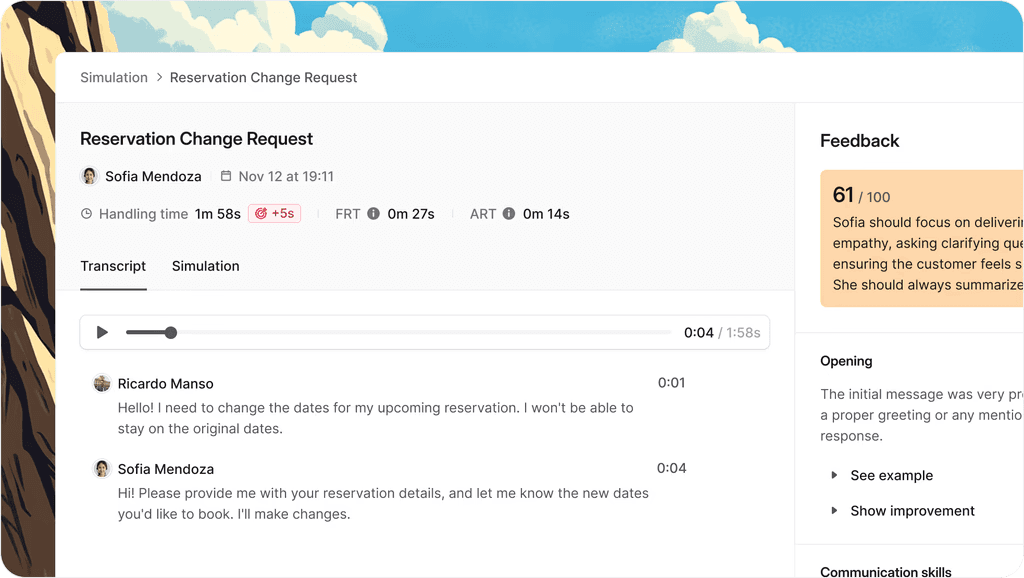
Solidroad is the only platform in this list that treats QA and training as a single workflow rather than two separate products. Our platform has scored more than 3 million customer interactions across chat, email, voice, and AI agent channels - and every quality finding can automatically generate a training simulation that puts the agent back in the exact scenario where they underperformed.
That matters because the harder problem isn't diagnosis - it's treatment. In our State of CX 2026 report - a survey of 500 customer support agents - we found that 82.5% of agents feel prepared when they start, but 53.5% say applying training to real situations is their biggest ongoing challenge. The gap isn't knowledge. It's practice. A scorecard finding tells an agent what went wrong. A simulation makes them fix it under conditions that mirror the real conversation.
Solidroad scores every conversation automatically across all channels, eliminating the blind spots that come with 1-5% manual sampling. Our platform reduces QA time per interaction by 90%. Solidroad's AI agent QA product monitors chatbot responses for hallucinations, policy violations, and incomplete answers in real time - based on platform data, 15-57% of AI agent responses contain errors before QA processes are in place. Solidroad's training simulations are auto-scored against the same custom rubrics that measure live performance.
Customers include Meta, Faire, Oura, Crypto.com, Ryanair, Podium, and ActiveCampaign. Per Solidroad, teams using the platform see a 33% faster agent ramp, a 20x increase in QA coverage, and 90% less time spent per manual review.
Solidroad's core limitation is G2 review presence - at 3 reviews, independent peer verification is harder than for more established platforms. Pricing is custom and needs a demo - teams that need a public pricing page for budget approval will need to work around this. Solidroad is built for mid-market to enterprise teams with 50+ agents; smaller teams at an early QA maturity stage may not need the full platform depth.
Solidroad is built for teams with 50+ agents that need QA to automatically trigger training, and for any team deploying AI agents that needs chatbot response monitoring.
2. Playvox (best for QA + workforce management in one suite)
Playvox is a contact center quality management platform combining QA, workforce management, gamification, and agent engagement tools in one suite. Now NICE-owned following a 2022 acquisition, Playvox is part of a larger enterprise CX portfolio.
Playvox combines quality management with WFM, gamification, and engagement tools in a single platform, reducing the number of point solutions teams manage. Its AI classifies feedback topics and sentiment at scale, giving quality managers a faster path to spotting patterns. Playvox integrates with major helpdesks including Zendesk, Salesforce, Freshdesk, Intercom, and Kustomer.
"Playvox Quality Management has been a valuable tool for streamlining our quality assurance processes. Customizable QA scorecards, clear performance insights, easy collaboration between QA and support teams." - Anchal J., G2 reviewer
Playvox does not include integrated training simulations - quality findings surface in coaching dashboards, but the step from score to behavior change is a manual workflow. Playvox is now owned by NICE Systems, which means product decisions are made within a large enterprise vendor structure - relevant for teams that prefer independent QA specialists. The full WFM suite carries enterprise-tier pricing ($70-$120+/agent/month), which makes it costly for teams that only need QA.
Playvox fits mid-market to enterprise digital-first support teams that want QA and WFM in one vendor relationship.
3. Scorebuddy (best for structured QA scorecards with built-in LMS)
Scorebuddy is a contact center QA platform with three-tier pricing, customizable scorecards, and a built-in LMS add-on - one of the more accessible tools for teams that want to evaluate before committing.
Scorebuddy's three-tier model (Foundation, Accelerate, Elite) lets teams start with core scorecard functionality and scale into AI autoscoring as their QA program matures. The built-in LMS add-on gives teams a path to connect QA findings to training content without a separate tool. The 14-day free trial makes Scorebuddy one of the more accessible options for teams that want to evaluate before entering pricing conversations.
"What I like best about Scorebuddy is how it combines structured, customizable scorecards with powerful analytics and coaching tools, making quality assurance both measurable and developmental rather than just evaluative." - Roce Jayne C., G2 reviewer
Scorebuddy's AI autoscoring is credit-based (500 credits/month on Accelerate, 1,000 on Elite) - teams with high interaction volumes may hit limits before the month ends. The LMS is a separate add-on with a manual connection between QA findings and training actions; there's no automated trigger that fires a practice scenario when an agent scores below threshold.
Scorebuddy suits small to mid-market contact centers upgrading from spreadsheet-based QA that want structured scorecards, modular pricing, and a path to LMS-supported training.
4. Observe.AI (best for enterprise speech analytics and compliance monitoring)
Observe.AI is an enterprise contact center intelligence platform combining automated QA, real-time agent guidance during live calls, and speech analytics for compliance monitoring. Its AI understands conversation context, giving compliance teams a scalable way to monitor regulatory adherence. The platform accommodates complex QA logic common in financial services and healthcare.
"Observe.AI stands out because it treats customer conversations as a real data asset - turning insights into coaching and performance improvements teams can act on right away, not just dashboards to look at." - Elizabeth H., G2 reviewer in consumer services
Multiple G2 reviewers note the platform needs a dedicated internal staff member to maintain it. Observe.AI does not include integrated training simulations; coaching recommendations surface from evaluations, but agents have no practice environment for the scenarios that scored them down. Enterprise pricing is not disclosed, and implementation complexity means total cost of ownership is higher than tools with faster self-serve onboarding.
Observe.AI is built for enterprise contact centers with 500+ agents, complex compliance requirements, and dedicated technical resources to maintain the platform.

5. EvaluAgent (best for automated QA with gamification and transparent pricing)
EvaluAgent is a UK-based contact center quality management platform with 100% automated coverage, per-user pricing, and gamification features. Its transparent pricing makes it easier to build a business case than tools that gate pricing behind a sales conversation.
EvaluAgent's per-user pricing (from £25/user/month for Auto-QA) is publicly disclosed - QA managers can build a business case and get procurement approval without entering a sales negotiation blind. EvaluAgent covers 100% of interactions with automated scoring and speech and text analytics. Its gamification layer - badges, leaderboards, and real-time feedback - gives agents more immediate visibility into their quality performance.
"I think the fact that EvaluAgent keeps the data centralized is very important to me. I also like being able to export and share data consistently without having to go through layers of BI and development work." - Andrew C., G2 reviewer
EvaluAgent includes LMS integration for training, but the connection between a quality finding and a training action is a manual process - there's no automated trigger that generates a practice scenario from a failing score. The platform's depth of data and navigation structure carry a meaningful onboarding investment. EvaluAgent's G2 review set shows a high proportion of vendor-sourced reviews in the data, which limits how much the review total reflects independent user sentiment.
EvaluAgent fits mid-market contact centers - particularly UK and European teams - that want 100% automated QA with transparent pricing and agent engagement features.
6. Level AI (best for AI-first conversation intelligence beyond standard QA)
Level AI is a contact center conversation intelligence platform that applies semantic understanding to QA, moving beyond keyword matching toward intent detection. Its Scenario Engine and Real-Time Manager Assist extend it past the QA core into broader CX intelligence.
Level AI's semantic intelligence engine understands the meaning of conversations rather than just matching keywords - AutoQA scores reflect genuine quality assessment rather than flagging calls that mention specific terms. Its Scenario Engine detects customer intent and maps the full conversation arc, giving QA managers access to voice-of-customer signals alongside agent performance data. Real-Time Manager Assist gives supervisors live visibility into active calls.
"What I like best about Level AI is how it combines AI-driven insights with human-level understanding. It doesn't just flag issues - it highlights trends, sentiments, and coaching opportunities." - Michelle R., G2 reviewer
Level AI does not include integrated training simulations - coaching recommendations surface from evaluations, but there's no automated path from a quality finding to a practice environment. G2 reviewers note that AI agent QA scores may need ongoing calibration to match company-specific standards - teams should expect a tuning period before scoring reliably reflects their rubrics. Pricing reflects a broader CX intelligence scope than teams that primarily want QA-only coverage.
Level AI fits mid-market to enterprise teams investing in AI-first conversation intelligence, moving beyond scorecard-focused QA toward broader CX analytics.
7. Zendesk QA (formerly Klaus) - best for teams already on Zendesk
Zendesk QA is the native quality assurance product within the Zendesk ecosystem, formerly known as Klaus before Zendesk acquired it. For teams already running support on Zendesk, it offers the lowest-friction path to QA coverage.
Zendesk QA is native to the Zendesk ecosystem - teams already on Zendesk Support or Suite add QA coverage without a separate integration or new vendor relationship. AutoQA analyzes every interaction including AI agent responses, and Spotlight automatically flags churn risk, escalations, and knowledge gaps without manual configuration. Zendesk QA correlates CSAT scores with QA performance at the individual, team, and department level.
Zendesk QA does not include integrated training simulations - quality gaps surface in dashboards, but agents have no practice environment connected to their scores. Zendesk QA is built around the Zendesk ecosystem: teams on Salesforce, Intercom, or Freshdesk should evaluate whether integration overhead makes it viable. Pricing is an add-on to existing Zendesk Support or Suite plans - for teams not already on Zendesk, the effective cost includes both the QA add-on and the underlying subscription.
Zendesk QA fits teams already invested in Zendesk that want native QA with AI agent monitoring and minimal integration overhead.
How to choose the right MaestroQA alternative
Choosing a MaestroQA alternative comes down to one question before all others: do you need QA to connect to training, or are scores and coaching recommendations enough? If your team's quality problem is diagnosis - finding gaps - any tool on this list will help. If the problem is behavior change - agents not applying what they learn - tool architecture matters as much as features.
Four questions to ask vendors before committing:
What happens after an agent scores below threshold? Does the system generate a practice scenario automatically, assign a learning module, or do nothing? The answer reveals whether QA-to-training integration is built-in or a manual workflow.
Does the tool monitor AI agent responses? If you're deploying any AI-powered support tool, ask for a live demo with an AI agent interaction, not just human agent examples.
What's the implementation timeline before your first scored conversation? A tool that takes eight weeks to configure has a very different switching cost than one with a 14-day trial.
What happens to your historical QA data if you switch again? Any vendor should be able to tell you what's portable and what isn't.
Frequently asked questions
The questions below cover what teams commonly want to know before switching from MaestroQA - the rebrand, pricing, and how different tools handle AI agent monitoring.
What replaced MaestroQA?
MaestroQA rebranded as Rippit in March 2026. Same underlying QA and conversation analytics capabilities remain, but the company has moved away from QA as a core identity. Teams evaluating alternatives typically look at Solidroad (for integrated QA and training), Zendesk QA (for teams on Zendesk), EvaluAgent (for transparent per-user pricing), and Scorebuddy (for structured scorecards with LMS access). The right choice depends on whether you need QA to connect to training, or whether scoring and coaching analytics are enough.
Is MaestroQA free?
No. MaestroQA (now Rippit) does not offer a free tier. Rippit.com lists pricing at "less than $100/month," which may reflect a post-rebrand SMB tier. Legacy MaestroQA enterprise pricing was $35K-$70K/year for 50-75 agents, per TrustRadius data. Pricing details for the current Rippit product are best confirmed directly with the vendor, as the rebrand brought pricing changes alongside the repositioning.
What's the difference between MaestroQA and Zendesk QA?
MaestroQA (now Rippit) was built for multi-helpdesk environments with complex scorecard requirements and has repositioned toward conversation analytics. Zendesk QA (formerly Klaus) is native to Zendesk - best for teams already on Zendesk who want QA without a separate integration. Zendesk QA's AutoQA monitors AI agent interactions; MaestroQA does not confirm this capability. Neither integrates QA with agent training simulations.
How do MaestroQA alternatives handle AI agent QA?
Most don't - these tools were built before AI agents became common in support operations. Solidroad's AI agent QA product monitors chatbot responses for hallucinations, policy violations, and incomplete answers in real time. Zendesk QA's AutoQA also monitors AI agent interactions. Playvox, Scorebuddy, Observe.AI, EvaluAgent, and Level AI do not confirm AI agent monitoring capability. For teams deploying Fin, Decagon, Sierra, or Intercom Copilot, this is a meaningful capability gap.
The bottom line on MaestroQA alternatives
The right MaestroQA alternative in 2026 depends on where your QA program is today - and what problem it's actually failing to solve. Tools that find quality gaps without closing them are half a solution.
Most QA tools in this list do the diagnosis well: they score conversations, surface patterns, and give managers data on where agents are underperforming. The tools diverge on what happens next. Coaching analytics can tell a manager which agents need help. Only an integrated training workflow makes sure those agents practice the conversation they failed.
Our survey data frames this clearly: 82.5% of agents feel prepared when they start. But 53.5% can't bridge the gap between what they learned and what the live conversation demands. That's not a knowledge gap. It's a practice gap. The QA tool you choose determines whether your program closes it or just measures it.
The MaestroQA rebrand accelerates the question for teams already on the platform. A vendor moving away from QA as its identity is sending a clear signal about where the product will invest.
See how Solidroad closes the loop
QA that stops at the score doesn't change agent behavior. Solidroad connects every quality finding to a training simulation so agents practice the exact scenario where they underperformed - not a hypothetical, not a refresher module, but the real conversation type scored against the same rubric.




© 2026 Solidroad Inc. All Rights Reserved